
Stop Waiting. Start Modeling.
The first development environment that catches typos, intelligently caches runs, and actually respects your time. Built to reduce wasted iteration cycles.

Taking the versatility of Jupyter notebooks and turning them into something with which you can iterate quickly, explore actual big data and productionize without the mess.
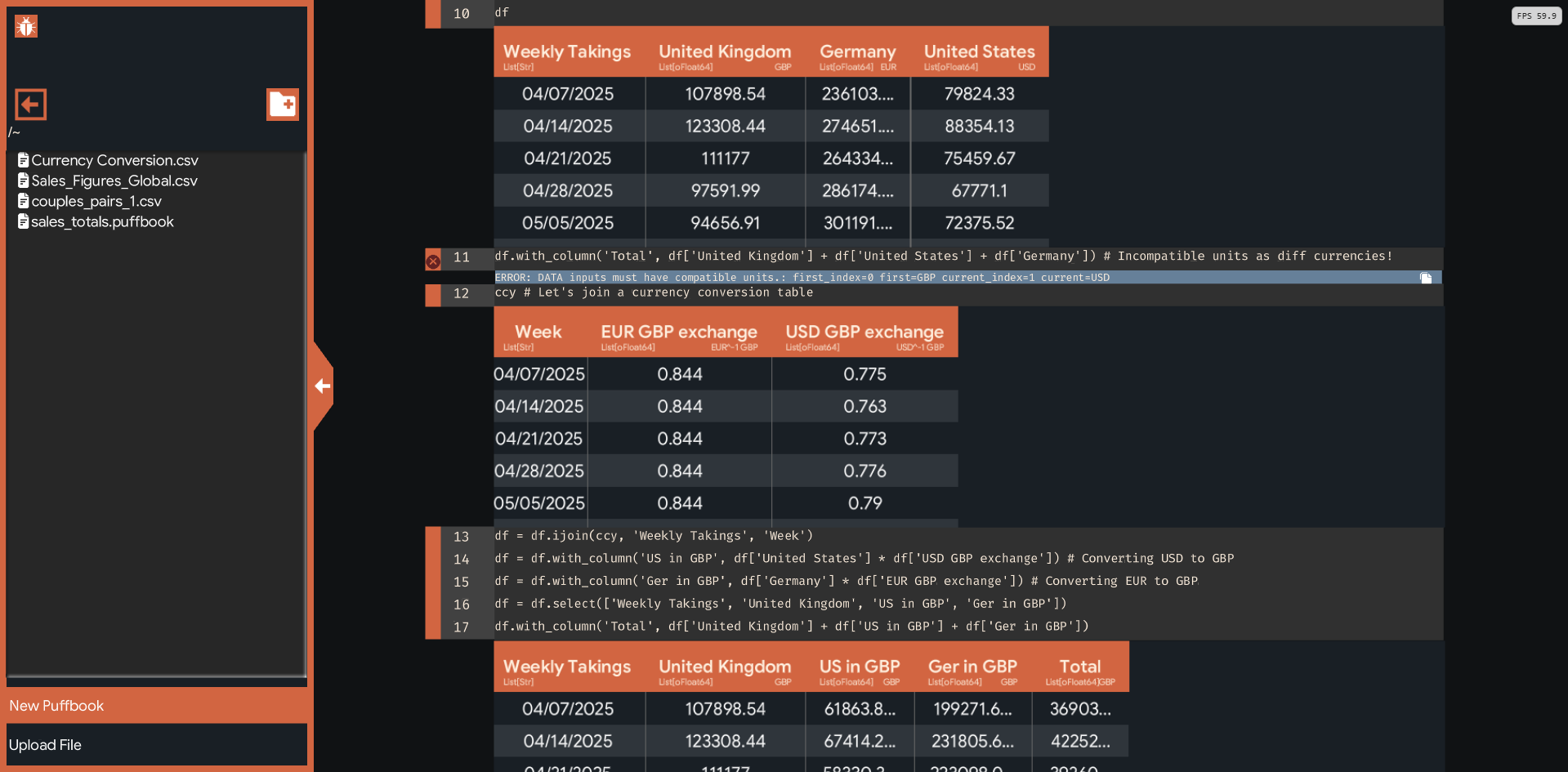
Fed up with this?
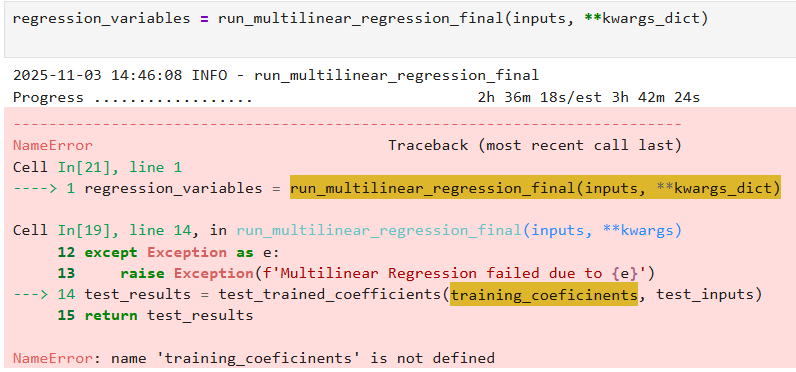
And also with this?
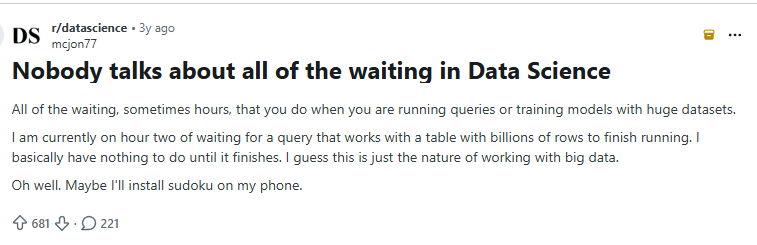
Where does your day actually go?
50-60% of the job is iteration, not insight
(a conservative estimate)
45%-60% of Data Scientist time is spent on data prep (BigDatawire, Forbes/Trifecta)
10-20% of developer time is lost to slow builds, slow runs, environment waiting or blocked execution (GitHub, McKinsey)
Only 20-30% of DS time is spent “modelling” (Kaggle/BurtchWorks) and modelling includes heavy iteration.
All that time waiting is pretty boring… and pretty frustrating…
Do Data Science Better with PUFF
PUFF is a notebook-style development environment built for iterative data science and quantitative workflows. We’ve designed it specifically to reduce dead time caused by reruns, crashes and slow execution cycles.
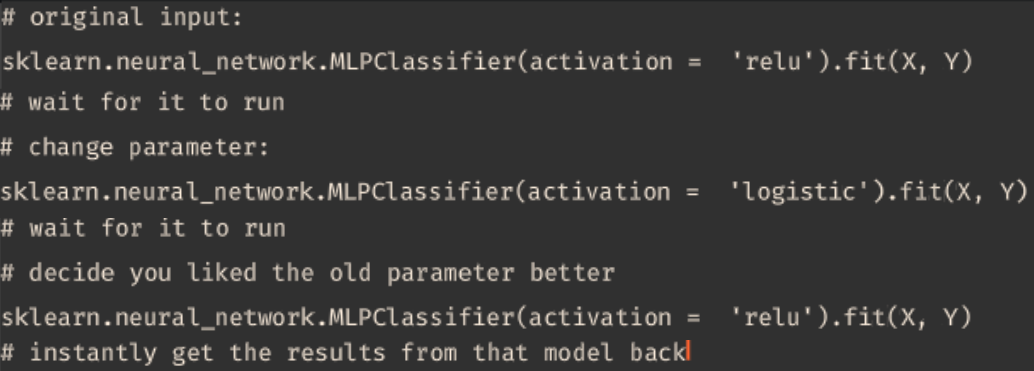
Incremental Computing
Only recompute the parts of your pipeline affected by changes instead of rerunning everything from scratch.
Big Data Exploration
Interact with large datasets directly without chunking files, crashing notebooks or exporting to Excel.
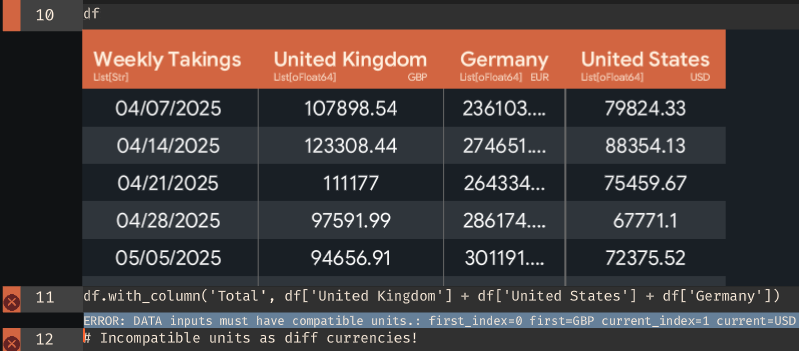
Early Error Detection
Catch typos, dependency issues and even mismatches in units or currencies before long-running jobs fail hours later.
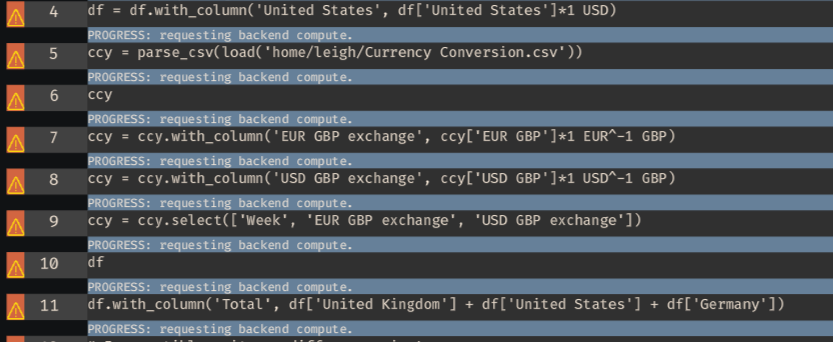
Parallel Execution
Run independent workloads concurrently instead of serially blocking iteration cycles. Requests are sent immediately, dependencies analysed run parallelized where possible
Built by Data Scientists. Engineered for Sanity.
We built PUFF after years of waiting for kernels to restart and pipelines to rerun just so we could test small model tweaks. We’re not a "magic AI box." We’re a better toolkit that reduces dead time through:
Incremental Computing instead of rerunning entire pipelines
Parallel processing built into the workflow
Standardised formats for painless pipeline handoffs
Unit & measure typing to prevent invalid operations

Full meta data lineage, licensing and encryption handled automatically

Many more things we’re not allowed to talk about yet….

Available now for early users!