
Your jupyter notebook IS NOT production - Part 2: Testing
Did You Break Production?
If you’re a data scientist who has broken production then well done, it's a right of passage. We've all been there. More than once.
If you’re a data scientist who KEEPS on breaking production, well you’ll want to keep on reading.
How To WORK As A Data Scientist
There is a lot of stuff out there that teaches you how to BE a data scientist but not a lot out there that teaches you how to WORK as a data scientist.
And yes, it’s cool and important to understand the theory behind a convolutional neural network, but to be honest, I forget the details.
I look it up on wikipedia to remind me whenever I need to use it. And ‘whenever I need to use it’ is, in practise, very rare.
That’s not to say all that learning is a waste of time, you do need good foundations to become a data scientist but let’s be honest. When your boss is trying to get buy in for your new demand prediction model, what do you think they care about more? Whether you had to refresh yourself on the model assumption or whether the model is actually going to work?
In my last post on this topic I already told you why your “production code” can’t be a stream of consciousness in a Jupyter notebook and spoke about how writing your code in clear functions is a prerequisite for putting something into production.
In the post before that I spoke about how having clear error handling is going to save your bacon in the inevitability that something does go wrong, even if that something is not your fault.
But if you’re not doing what today’s topic is about, then something going wrong is likely often going to BE your fault, so let’s address that one head on. Today we’re going to talk about testing.
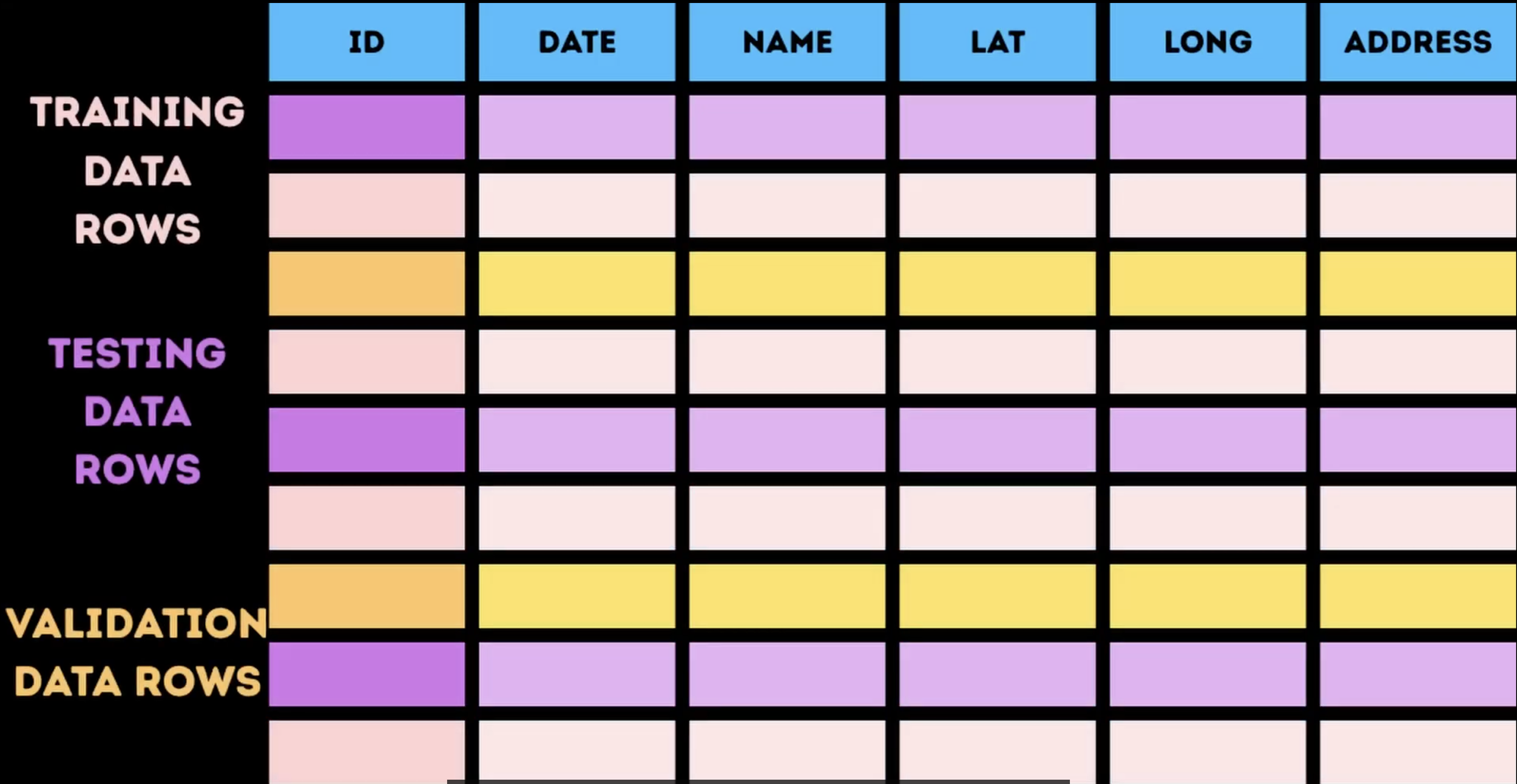
Image highlighting that production testing is separate from train/test/validation splits
This Is Even More Important for Vibe Coders
When I talk about testing I’m not talking about the kind of testing you do when you’re building your model for the first time where you split your model into train, test, validate and all that good stuff.
The testing I’m talking about today is specifically to make sure that once you’ve got things into a state in which you’re happy with it, they stay that way.
Because even on small projects, we’ve all tweaked the code slightly and then found out something else has stopped working and needed to backtrack to find out what was wrong.
Now scale it up to big projects where you’ve forgotten what that bit of code did only to remember when fixing the thing you just broke, or projects shared across multiple people where you’re breaking each other’s code constantly.
And by the way, if someone is breaking your code. That’s a YOU problem. YOU didn’t put enough tests in to prevent that.
And even if we take this to the most 2026 view point ever of: “Well I’ll just get Claude to write all my code for me” then I have bad news for you.
You can tell Claude not to break the existing code until you’re blue in the face and it doesn’t matter. It’s an LLM. It’s going to break it anyway.
In today’s Data Science world, writing tests for your code is possibly the most important and most undervalued skill out there so today we’re going to cover the most important parts of testing you need to know to WORK as a data scientist, starting with the one I am most passionate about. Let’s talk about unit testing.

Image showing the data cleaning process split into smaller, reusable steps
Unit Testing
So in my post about functions, I wrote about how it’s important to break your code up, to group it into similar functionality so that you can understand it and work with it easily.
For example, if you have a large amount of data cleaning to do, you might have a big function called data cleaning and inside that data cleaning step break it down into smaller chunks like a step that re-formats the column types. A step that handles missing values. And a step that combines multiple columns to make a unique primary key.
Each of these small steps can be considered a unit. Something that has just one behaviour to test. At the start of our re-formatting column types unit, all the column types are wrong. At the end, all of them are correct. That’s a single isolated bit of functionality.
That makes them incredibly easy to test, and that’s basically what unit testing is: Going through your code and writing small tests that test isolated functionality so that you know you haven’t broken it.
The important thing to note is that once the tests are written, they are set up to run automatically whenever a change is committed for the underlying code and will give you a pass/fail report. This means that if you make a change and it breaks something, the corresponding test will tell you and you can fix it now instead of waiting for the angry email the next day when your model no longer works.
So what does a unit test actually look like? At its most basic level, you give it a simple example of an input, and ask it to check that the output looks like what you expect it to.
For example, say we have a function fill_null but let’s make it a little interesting so it’s not just doing something basic.
Say you have a name column and want to default all missing names to “Jane Doe” and an age column and you want to default all ages to the average age of the sample because not many babies under one have the finger dexterity to fill out a form. But maybe there are other fields you want to default to something more normal. Address to an empty string. Number of times visited to zero.
In this case, your input table would look something like this:
There are enough columns to cover all our bases: Name, Address, Age and Visits, but only a few rows of actual data, with nulls in each column so we can test the result. Our unit test looks a bit like this:
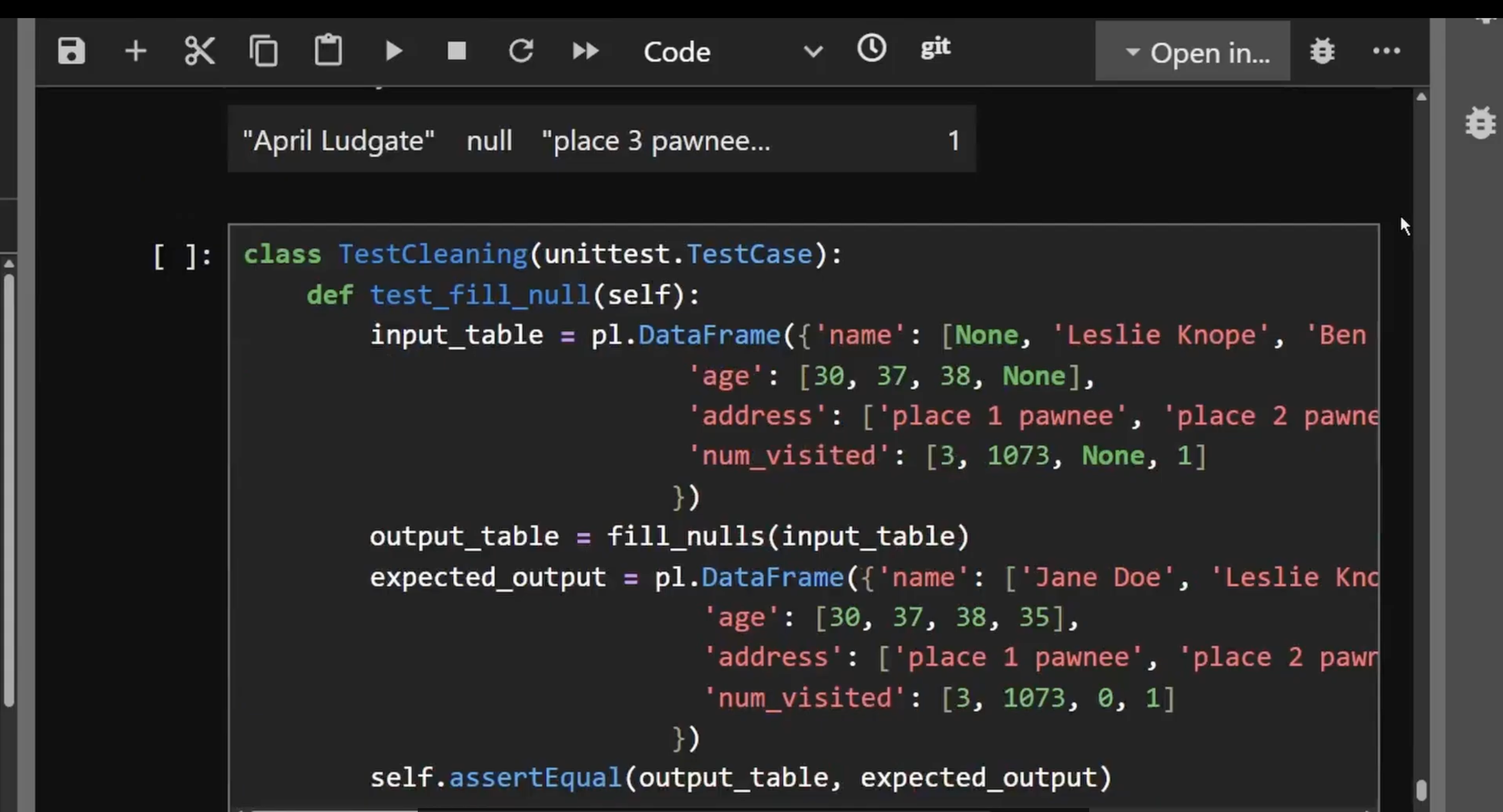
Def test_fill_null():
input equals the table I gave you earlier
Output = fill_null(input)
Expected_output which is hardcoded as the input table but with the nulls replaced by the values you expect to be there: Jane Doe, the average of the age column, empty string and zero. The final line is basically assert the input is equal to the output.
I have SO MUCH to say on this topic of unit testing that I reluctantly cut out of this script to stop this post becoming overloaded so if you would like to read a post going deeper into what unit testing is and how to do it properly, make me happy and let me know via our discord.
For now, the last thing I’ll say about unit testing is that I’ve worked with people who took unit testing seriously, and people who just did it because a company rule was that we had to do it. The ones in that latter group were fixing bugs far more than the rest of us.
Alright so step number one, our basic functionality doesn’t fall apart. How do we make sure the code still does what I actually want it to do?
Regression Testing
So you put out a new version of the predictive model and all of a sudden the next day it predicts sales of chocolate will quadruple. Unless you’ve just put the mini eggs out for Easter and expect this change to happen, it’s probably fair to say that this is suspicious and might mean there’s something in the model has changed, and maybe not in a way you expect.
Unit tests can sometimes catch this problem, if you have a unit test that expects a specific number for a specific set of inputs then it might catch a big change to the numbers early. The problem is that you can only write so many unit tests and the real world has edge cases that you might not even have thought about. Instead of writing unit test after unit test for every single scenario under the sun, instead you want to look at something called regression tests.
Regression tests effectively run both the old and new model on the same data and look at what changed. You take the outputs of both, put them side by side and flag anything that is different as interesting.
What’s important to note about regression testing is that unlike unit testing, a flagged regression test isn’t necessarily a bad thing. Sometimes the numbers will change because you genuinely improved the model. Maybe you specifically adjusted how the model works for pet food. Then if the flagged rows include crunchies, hay and dog treats, these are probably an expected change and you wouldn’t consider that a fail.
But if you had only adjusted the model for pet food and there were big changes in chocolate, probably something went wrong and you need to take a look at that.
The purpose of regression testing isn’t to get a straight up pass and have nothing change. It’s to make sure all the changes are explainable.
There’s a little elephant in the room though when I talk about explainability. When it comes to machine learning, not all of it is explainable. So let’s talk about non-deterministic functionality.
How to Deal With Randomness
If you’re building a non-deterministic machine learning model, you can give it the same inputs over and over and over again and get a different output every time.

Can you spot the differences between these images?
That is literally the definition of non-deterministic. There’s some randomness in there that means we can’t precisely predict the output.
Now in many ways, that’s desirable. The randomness of these models is a feature, not a bug. It’s what fundamentally enables stochastic gradient descent which is now a fundamental building block to deep learning.
Trying to build a unit test or regression test for something that gives inconsistent outputs is like writing a test that asks ChatGPT a question and looks whether it gives the same answer every time.
There are a few ways in which we can handle this. The first is that for many models, we can set the random seed. Random number generation in computers isn’t technically random, it’s pseudorandom.
The numbers aren’t randomly plucked from thin air, they’re generated by an algorithm, one that is designed to make the numbers appear random when really, they’re deterministic.
However, that doesn’t mean that every time you ask for a random number you’re going to get the same thing. Instead the starting point of the algorithm is usually varied so that you do get different numbers each time, making it seem random. This starting point is known as the seed.
If you understand this, you can do pretty cool things. I once watched my partner get frustrated playing xcom because it kept crashing. Every time he re-loaded the turn it would crash yet again no matter what he did. Whatever instance of randomness had been generated for that turn was causing a bug in the game that was about to ruin his save file.
So I suggested he try going back two turns instead, so he did and I don’t remember now but I think he tried to play the turn in the exact same way as the last time.
When he got to the next turn, he was able to get through it with no bug. Going back a turn had changed the game's sequence of random events, which was enough to avoid whatever bug had been causing the crash. So there you go, data science saves save files kids.
But knowing that you can modify the state of the randomness, you can use the exact same thing in your tests. Set a fixed random seed at the start of the test and because pseudorandom generators are deterministic, you get the same sequence of “random” values every time, meaning that if the results changed, you know it’s your fault, not RNG.

Image of code with setting the seed on screen
Of course sometimes this isn’t possible. You probably can’t set ChatGPT’s seed for one thing. In this case we want to test that we’re in the right ballpark rather than an exact match. We could do things like testing whether the result is within a certain range or whether a series of results follow an expected distribution.
But we’ve hit a key point here, testing does become so much harder when you’ve got to use someone else’s stuff instead of writing things on your own. What do we do about that?
Honourable Mentions
So this last section is for my honourable mentions.We’ll start with one that likely would be offloaded to your data engineer if you have one: Integration tests. Things like: when you ping the api, do you get a result back? Can your model still read data from the lake? Do all the pieces of the system fit together?
We also haven’t covered edge case testing. If you have a form expecting numbers and someone dumps a load of text in there, what happens?
And we could even talk about something as basic as sanity testing: Do these results make sense to you as a human interpreting them? If your model says the average age of children at nursery is 74, are you really going to say “The code worked so everything is fine!”?
All of these are still relevant to data science, but if you understand unit testing, regression testing, and how to handle randomness, you'll have the tools to prevent most bugs before the angry email derails your entire day.
Our closed beta is now Live. Sign up via the link below and keep being Evil